
ScratchDB Update
2024 Notice: This post is outdated and things have changed. A writeup of issues with this plan should hopefully be released soon. This post remains here for posterity's sake
The ScratchDB project began a few years ago as a way to watch the Scratch forums to see what the Scratch Team deleted, in response to one of my friends posts being consistently deleted for random reasons, trying to find trends. In the end, I never really analyzed that data or looked much further into it as the project rapidly grew beyond that initial purpose. Since that initial revision, ScratchDB has seen 3 or so major updates, going from purely a forums replica, to being a quite filled database projects, users, and of course forum posts. When I initially wrote ScratchDBv2 and ScratchDBv3, I was getting started and getting the hang of JavaScript API development. These revisions were completed in early High School and have since then seen very little updates; some features in v2 never even made it into v3 due to how I structured the parsing system.
Fast forward a few years, I am currently a student at Georgia Tech in Atlanta studying Computer Science. Even with only 1.5 semesters of college-level programming knowledge (besides the ??? years of self-taught information) I have seen many aspects of ScratchDB that could be revised or improved on. I currently have no plans on fixing what was in v2 or v3, as at this point I bet I could barely recognize much of the codebase, but I do have a plan in mind, and hopefully in the next few weeks things will start falling together.
A New Plan
ScratchDBv3’s database is the same database as ScratchDBv2, and they both use the same indexing system (actually, the same one, only one instance feeding the same database they pull from), and its held up quite well, but it is starting to show its age in its parsing and timing setup.
Since starting school, I’ve gotten a decent grasp on how OOP should be done, as compared to the mess of JavaScript that made v2 and v3, so in the future, anything new should be a bit easier for me to manage.
Starting out, the main part that I need to replace is the ranking system. Currently v2 stores all of this information on ram when it starts up (takes a good 3-5 minutes to read and parse), while v3 keeps a rolling update in Redis. In v4, I plan on moving to a central place to keep all live ranking data, rather than reading from a database. To begin this new project, I will create an open-source database in Rust (🚀) that handles nothing but keeping a rapid up-to-date database of ranks as the indexing system pulls in updates. This would go for the following categories:
- follows
- followers
- total project loves
- total project favorites
- (the same 4, but per region)
I may try to do per-project rankings, but that is down to how well I can manage memory in this new revision (and once it is open-sourced, help would be greatly appreciated!)
So next comes the indexer. In its current state, the mess of JavaScript works surprisingly… okay… but it could be definitely improved. Currently it is a single node process that has some loose idea of “threading” but in practice it’s really just single-threaded. This isn’t a terribly large issue since I get data so slowly (Scratch banned my home IP a good 4 years ago, so I’ve instead distributed the workload to a few hundred free live proxies since I don’t make money from the project). This system works well, and I definitely plan on taking parts of it in my new revision of it, but the system really needs to have proper threading, and a new timing system.
Currently for timing, everything is up to selecting a time in the database, hoping it doesn’t fall behind from what it set previously. (I’m not explaining this very well, basically, once it gets info on a user, its puts the updated user info into the database and also calculates a time the user should be checked next, then hopefully at that next time the indexer isn’t overwhelmed and can index them again) This system has worked, but it has been left up to some very simple math, rather than what really matters: user interaction. I’ve gotten a lot of complaints on how slow people are updated on the site, and I hope I can fix this issue in the next revision. Perhaps indexing and serving live rather than serving possibly months-old data. So, for this next system, I hope to either re-write it in TypeScript (which I now have some knowledge of), or Go (purely to get some learning in it).
Lastly comes the front-end API. Currently the v3 API heavily relies on caching to not have to touch the database too much. In v4, this will be changed to talk mostly to the Rust (🚀)-based database discussed earlier. Otherwise, much of the API should be similar to v3’s, since on its own its had most every endpoint people have needed.
Another addition will be live data. Currently v2 and v3 serve old data, with v4 I hope to provide some “lightning” endpoints that’ll give up-to-date data of a user or a category. This may also include some form of websocket for forum posts, since some people have requested getting more rapid updates there.
When it comes to the actual implementation, I will keep it quite similar to v2 and v3, being an Express based API, this time being TypeScript instead of simple Node, to keep things a bit more clean. I plan on possibly open-sourcing the new API, but this is by no means a promise.
Why?
So I’ve left this project go dormant for quite some time, and people are starting to wonder when it’ll simply go offline or disappear. I’ve simply moved on to many other things, and also quite a bit of not doing much new development since then. I’m now taking some classes relating to data structures and algorithms, and these have shown how much better ScratchDB could be.
The second part is my resume. Currently my resume has a lot of “JavaScript” and really nothing else, this gives me an excuse to learn Rust and possibly Go in a high-performance, high-volume environment that would be very helpful in the future to know. This also lets me get back into making open source software, since the previous revisions have been kept closed source, where they don’t show my programming knowledge at all, besides results shown. By open sourcing some parts, it shows what I do know, and also shows where I can improve.
The last thing that caused this update is, surprisingly, my English class. The course operates where by the end of the semester I need to research and provide a result, and in this case, my research is designing a new database and more proper methods to building this system, and the result is most of the code, and of course the new API. I don’t expect this project to be finished by the end of the semester, but perhaps some pieces will start to fall into place.
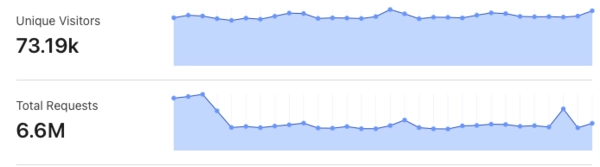
ScratchDB has been the peak of what I’ve made so far, processing terabytes of data and serving millions of requests (see photo below), and I really don’t want to let the project go gently into that good night. I would like to provide something that I feel I could show people, and explain how it works in the backend. By making ScratchDBv4 I can finally do this.
This project feels a tad ambitious, being an effective full rewrite and possibly a full re-index, but at the end of the day, its experience that I can use in the future. I’ve been asked, “why do you run this when you aren’t paid anything?” and the answer is that it’s simply fun to run and provides a great thing to have on a resume, as it shows I can work with large projects with large real-world datasets.
Hopefully along the way I can provide some updates, although based on my track record of a lot of radio-silence (side note: I am a DJ on WREK 91.1 FM, although I currently do things at midnight [Thursday morning, Wednesday night] so not too much going on there), I may not. I guess we shall see.
~~Scratch On!~~
Tl;dr
- ScratchDBv4 should hopefully be coming soon
- I am now no longer in high school and somehow made it into a university
- pieces of it will be open sourced and may require some help
- old JavaScript is messy
- this project isn’t dead even though no updates have come out in over 2 years
- None of this may happen, but it should hopefully be happening
Whelp, here goes nothing!
(at this point, the writing is over, below this I’m just having some transparency)
Extra Info
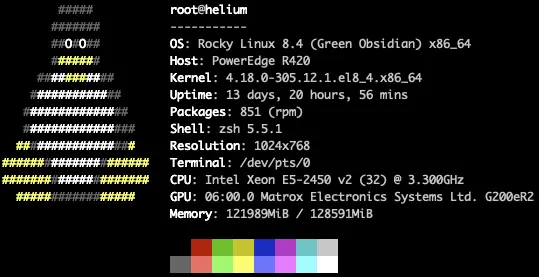
Also, for those who have asked here are specific numbers in relation to storage, processing, and requests.
Server Specs:
Numbers (As of posting):
- 12,756,854 users
- 6,138,400 forum posts
- 572,355 forum topics
- 1,905,424 forum edits
- 94,633,751 projects
- 61,693,216 pieces of user history
- 2.84TB of project JSON
- 292.6 GiB of MySQL databases
Counts given my PHPMyAdmin guesses and ZFS data